2019年度卒業生のゼミ論文である「YouTuber 東海オンエアについての考察 ~投稿動画のコメントから東海オンエアの人気を分析〜」の内容を紹介しました。
この研究では、再生回数が多い動画と少ない動画のコメントを分析することで、再生回数が多い動画の特徴を調べました。その結果、視聴者から特に注目されている動画内ポイントとして、メンバーの謎の動き、ふと出た言葉、巧みな言葉選びといったことが指摘されています。
この研究では、学生が目視で3000以上のコメントを1つ1つ確認して分類したため、大変な作業だったと思います。本人が好きなYouTuberだからできた研究と言えます。
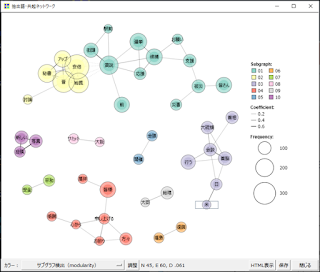
今回のゼミでは、YouTubeからコメントを取得して、テキストマイニングする方法を説明しました。テキストデータをコンピュータで定量的に解析し、有用な情報を取り出す技術のことをテキストマイニングと言います。様々なソフトウェアがありますが、今回はKH Coderを用いました。形態素解析して、単語の使用頻度を調べたり、共起ネットワーク図を描いたりすることがプログラミングなしで簡単に行えます。投稿内容の傾向を大まかにつかむことができます。大量のコメントでも、簡単に分析ができます。しかし、詳細な分析をするには人間がコメントを読むしかないでしょう。